2 What is Machine Learning?
In data science, “machine learning” refers to a set of mathematical algorithms that use a dataset to classify or estimate data by learning. In science, we might use machine learning to identify clusters or patterns in big datasets that help form new theories. In healthcare, we might use machine learning to predict risk for a patient developing a disease based on characteristics of previous patients who did or did not go on to develop that disease. In business, we might use machine learning to predict whether a new user might like a product based on other similar users’ ratings- that is, generating personalized product recommendations. Therefore, machine learning is one of the only known ways to predict the future! These models can vary from simple algorithms you already are probably familiar with, like linear or logistic regression, to algorithms you probably are not familiar with such as Decision Trees, K Nearest Neighbors, Naive Bayes, Support Vector Machines (SVM), and much more!
Many people conflate machine learning with artificial intelligence or deep learning, but that is often not what data scientists are using when they work with machine learning algorithms. Artificial intelligence is a broad concept of creating machines that can mimic human cognition. Machine learning is a subset of artificial intelligence that automates the process of learning from data to improve performance without being explicitly programmed for each task. There are many levels and branches of machine learning that vary widely in their application and function. The simplest version can be a logistic regression, while the fanciest versions are so complex even the designers do not completely understand what the computer did to get the output values. These computing “black boxes” are often what people envision when they hear the term “machine learning”. Machine learning can be an invaluable tool for a data scientist even without reaching that level of complexity.
A major difference between standard modeling practices and machine learning is that standard modeling practices require you to select your model structure* ahead of time, in machine learning, you don’t know what model is the most predictive initially. You cannot choose a model based on characteristics of your data alone. Instead, the characteristics of your data can tell you which class of algorithms to investigate, but the only way to determine which algorithm should be used to predict new unseen data is by running all the algorithms that are relevant (or that you have time and computing power for) and compare how well each performs on unseen data to select the most predictive model to use going forward. Machine learning algorithms differ from traditional modeling practices in how we evaluate how “good” the model is. In Machine learning we are primarily interests in how accurate the model is in predicting new, unseen data so we focus on evaluating what models do best at that task. In tradition modeling, we are primarily interested in how well the model describes the variance in the existing dataset.
A helpful way to understand machine learning is to tie it to what you (probably) already know and use. Let’s take a step back and discuss how linear regression is used in machine learning to highlight the difference between machine learning and the models you already use. On their own, regression analyses describe a pattern or relationship between variables in data without making predictions about how new data would map onto trends. In traditional linear regression the goal is to interpret the results to make inferences about how the outcome and predictor variables relate to each other. Traditional linear regression does not allow for prediction values of new unseen data. In machine learning, linear regression can be used for inference or prediction. By adding in steps that optimize performance like cross validation, hyperparameters, and regularization you can create a model that can accurately predict new, unseen data as well as do inference. A crucial step in turning inference to predictive accuracy is cross validation. Cross validation is the process of partitioning the data into training and testing sets, fitting models on the training data, that are then validated on the testing data. By testing your model on new data that wasn’t involved in creating the model, you can estimate how well your model will do on data you have yet to collect!
2.1 Definitions
While I mentioned in the overview that I am not going to be covering deep learning (aka neural nets), semi-supervised learning, unsupervised learning, or how to deal with quantitative predictions, It’s helpful to feel like you are hip with the lingo if you know the difference between all these terms. The difference between supervised, unsupervised, and semi-supervised is very simple. In supervised learning your data has predictors and an outcome variable. In unsupervised learning your data has predictors, but no responses. Instead of looking at how your dependent variable is impacted by an independent variable, unsupervised machine learning has a number of independent/predictor variables and looks to create groups within data based on similarities and differences. For example, we might be interested in predicting what regions of the brain show similar connectivity patterns, without having any prior knowledge of what regions are functionally related. In semi-supervised your data has a mix of both: some of your data has responses and some doesn’t, and you do a mix of both methods on each subset of the data. Deep learning is a term that means you are using a specific model class called neural networks. Neural networks can be either supervised, semi-supervised, or unsupervised. It just depends on what kind of independent and dependent variables you are feeding the model. For more information on when to use what algorithm see this blog post. There are more models within machine learning than would be possible to speak on and more are being created as I write this. Some of these models can be used in both classification that I discuss here and regression, but I will only be discussing them in terms of classification.
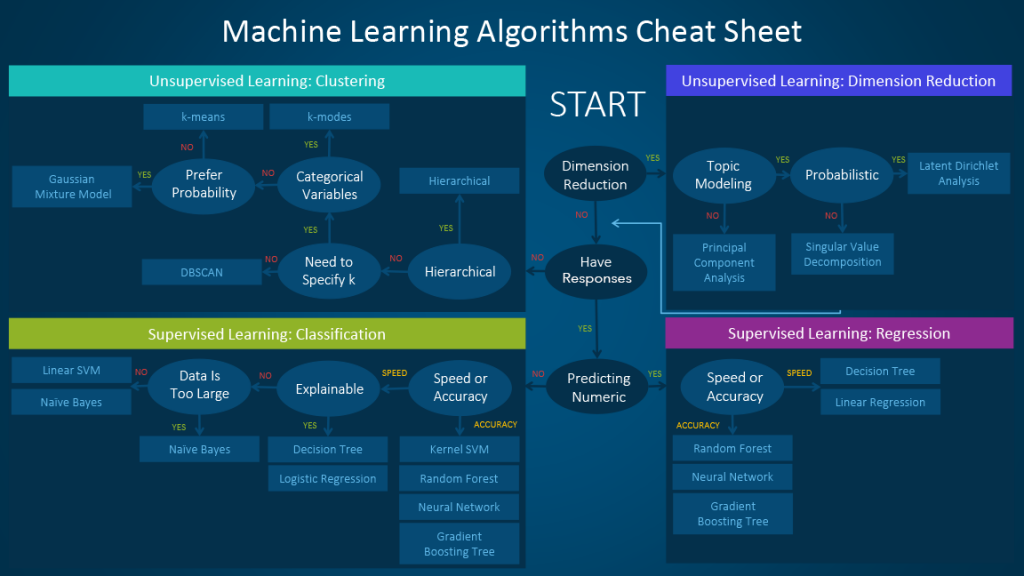 Source: The SAS Data Science Blog (https://blogs.sas.com/content/subconsciousmusings/2020/12/09/machine-learning-algorithm-use/)
Source: The SAS Data Science Blog (https://blogs.sas.com/content/subconsciousmusings/2020/12/09/machine-learning-algorithm-use/)
2.2 The Case for Machine Learning
If you already use standard modeling practices why should you learn machine learning? That question should be answered by a large group of statisticians arguing at a conference, but in the mean time, I am going to give a few brief arguments for Machine learning to be more widely used in social sciences. Machine learning is worth the time to learn because it can help alleviate some of the systemic replication issues in psychology and other fields as it is a more analytic process of making claims with data. It also allows for prediction instead of just inference. Current modeling practices often have some form of subjective decision making. We choose a theory a priori, we run some tests that are designed to support our theory (in principle we run tests that challenge our theory but in reality we often set ourselves up to do the opposite, if we are doing null hypothesis testing), and there are countless decisions we make in the meantime to shape the data into results consistent with our theory. Machine learning bypasses some of this by letting the analysis follow the data, using the characteristics of the data to make some of those decisions rather than human subjectivity. While primary research on the pros and cons of machine learning is an emerging field multiple studies have found benefits over traditional methods (Medeiros et al. 2021; Grant et al. 2022). Some sources suggest integrating standard modeling practices with machine learning to get the most accurate results (Rajula et al. 2020).
* Even in iterative analyses, where information from one step is used to inform the analytic decision at the next step you still need to specify the terms of each step of that iterative process before you run it. Unlike Machine learning, which is adaptive and can automatically adjust and learn based on the data.